This article is written based on the lecture MATH532 by Prof. Hwang at POSTECH.
What is Gradient Descent Algorithm
In machine learning, we usually have to find a way to minimize a target function (e.g. MSE). How can we find the minimum of the target function if it is too complex to find analytically? Think about the basic calculus you learned in your freshman year. There was a notion called “Gradient,” which points in the direction of the steepest slope. Its magnitude also means the rate of increase or decrease of the function in that direction. Therefore, the gradient is very useful for finding minimum or maximum values in that it points where we need to go to find our destination. Of course, we have to follow the opposite direction of where the gradient points. This can be written as
$$ w_k = w_{k-1} - \eta \cdot \nabla_w J(w_{k-1}) = w_{k-1} - \eta \cdot \nabla_w \sum_{i=1}^{N} L(w_{k-1};x_i,y_i) $$
where \(J(w) = \sum_{i=1}^{N}L(y_i,\hat{f}(w;x_i))\) and \(L\) is a loss function.
Limitations

https://www.reddit.com/r/ProgrammerHumor/comments/eez8al/gradient_descent/
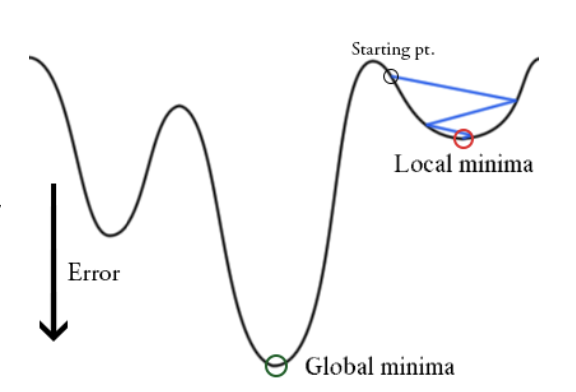
Simple gradient descent algorithm has several limitations.
-
If the starting point for gradient descent was chosen inappropriately, the algorithm will only make it approach a local minimum, never reaching the global one.
-
We need to compute \(\nabla_w L(w_{k-1};x_i,y_i) \)for all \(i\) to perform one update. Hence, it can be very slow and is intractable for datasets that don’t fit in memory.
Stochastic Gradient
One method to overcome the limitations alluded to before is the stochastic gradient descent. It is literally the stochastic approximation of gradient descent optimization.
We select data size \(B\) from all sample size \(N\). Then we can iteratively calculate parameter \(w\) where the loss function is being minimized. This can reduce the computational burden. Also, there is a fluctuation in the objective function since we select the \(B\) data randomly. This fluctuation enables it to jump to new and potentially better local minima.
$$ w_k = w_{k-1} - \eta \cdot \nabla_w \sum_{i=1}^{B} L(w_{k-1};x_i,y_i) $$
Momentum Methods
This is the most interesting algorithm in the class today! When we drop a ball on a complex loss function surface with proper friction, the ball is likely to pass through local minima and arrive at the global minimum. This is because as the ball moves downward, its potential energy transforms into kinetic energy so that it gains enough energy to pass through local minima. Momentum methods are inspired by this physical phenomenon. The name momentum comes from the fact that the negative gradient acts as a force moving a particle through parameter space (although it is not exactly the same as classical momentum).
The algorithm can be expressed with equations as below.
$$ v_k = \gamma v_{k-1} + \eta \cdot \nabla_w \sum_{i=1}^{B} L(w_{k-1};x_i,y_i) $$ $$ w_k = w_{k-1} - v_k $$
Here, \(\gamma\) plays a role as a friction. (Although not exactly the same.) It is a method that helps accelerate SGD (Stochastic Gradient Descent) in the relevant direction and dampens oscillations. Also, it can help escape local minima.
Nesterov Accelerated Gradient
Momentum method adjusts the momentum based on the current position $w_{k-1}$. On the other hand, Nesterov Accelerated Gradient is based on the approximated future position $w_{k-1}-\gamma v_{k-1}$.
$$ v_k = \gamma v_{k-1} + \eta \cdot \nabla_w \sum_{i=1}^{B} L(w_{k-1}-\gamma w_{k-1};x_i,y_i) $$ $$ w_k = w_{k-1} - v_k $$
Adaptive Method
AdaGrad
As I alluded to before, in order to arrive at the global minimum, not a local minimum, we need to have an appropriate parameter $\eta$. Too small $\eta$ can cause too slow convergence, and too large $\eta$ can cause too much fluctuation to converge. Also, having a constant $\eta$ is not suitable for complex loss functions.
AdaGrad (Adaptive Gradient) is an algorithm that adjusts the learning rate automatically. It updates more for infrequent parameter and less for frequent parameter. The algorithm can be written as $$ g_{k-1,i} := \nabla_w J(w_{k-1}) $$
$$ G_{k-1,i} = \sum_{t=0}^{k-1}|g_{t,i}|^2 $$
$$ w_k = w_{k-1} - \frac{\eta}{\sqrt{G_{k-1,i}+\epsilon}} g_{k-1,i} $$
As the accumulated gradient gets bigger, the learning rate gets smaller.
RMSProp
AdaGrad has some weaknesses due to the denominator $G$. Since $G$ increases monotonically, the learning rate shrinks and eventually becomes very small, so the algorithm cannot learn anymore. If we change the summation of $g_{k-1,i}$ into a running average, this problem can be solved. RMSProp averages previous $g$ and current $g$ with weights $\gamma$ and $1-\gamma$ respectively.
$$ g_{k-1,i} := \nabla_w J(w_{k-1}) $$
$$ E[g^2]{k} = \gamma E[g^2]{k-1} + (1-\gamma) g^2_{k-1} $$
where $$ E[g^2]{k} = \sum^{k-1}{i=0}(1-\gamma)\gamma^i g^2_{k-1-i} $$
and $$ w_k = w_{k-1} - \frac{\eta}{\sqrt{E[g^2]{k-1}+\epsilon}} g{k-1,i} $$
AdaDelta
AdaDelta is another extension of AdaGrad. AdaDelta focuses not only on the denominator but also on the numerator.
$$ g_{k-1,i} := \nabla_{w_k} J(w_{k-1}) $$
$$ E[\Delta w^2]{k} = \gamma_1 E[\Delta w^2]{k-1} + (1-\gamma_1) \Delta w^2_{k-1} $$
$$ E[g^2]{k} = \gamma_2 E[g^2]{k-1} + (1-\gamma_2) g^2_{k-1} $$
and $$ w_k = w_{k-1} - \frac{\sqrt{E[\Delta w^2]{k-1}+\epsilon}}{\sqrt{E[g^2]{k-1}+\epsilon}} g_{k-1,i} $$
Adam
Adam is an algorithm that combines RMSProp and Momentum. It was proposed by Kingma & Ba. It not only keeps the average of past squared gradients like AdaDelta and RMSProp, but also keeps the average of past gradients. Since initial averages are biased towards zero, Adam adjusts them to be unbiased.
$$ g_{k-1,i} := \nabla_{w_k} J(w_{k-1}) $$
$$ m_{k-1} = \gamma_1 m_{k-2} + (1-\gamma_1)g_{k-1} $$
$$ v_{k-1} = \gamma_2 v_{k-2} + (1-\gamma_2)g^2_{k-1} $$
$$ \hat{m}{k-1} = \frac{m{k-1}}{1-\gamma^{k-1}_1} $$
$$ \hat{v}{k-1} = \frac{v{k-1}}{1-\gamma^{k-1}_2} $$
and $$ w_k = w_{k-1} - \frac{\eta}{\sqrt{\hat{v}_{k-1}}+\eta} \hat{m} _{k-1} $$
Code
You can get the gradient descent code I wrote from scratch.
https://github.com/MunjungKim/Gradient-Descent-Algorithm
Reference
-
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition. New York: Springer Series in Statistics
-
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An introduction to statistical learning (Vol. 112). New York: springer.